AI/ML Streaming patterns with Apache Kafka
Exploring AI/ML streaming patterns with Apache Kafka, from traditional batch pipelines to real-time model training, online learning, and RAG-powered LLM applications.
Before exploring the structure of modern AI applications, it’s important to understand the foundations of Machine Learning (ML) pipelines which they grew from. Previously models were trained on snapshots of data but now they rely on continuous data flows. This article will give you the broader context in where enterprise AI and ML sit, and what the architectural options are.
Data-streaming platforms such as Apache Kafka have become foundational in this shift. They provide the ability to ingest, process, and route data at scale, enabling models to be trained, evaluated, and served using fresh, high-velocity data. This unlocks new possibilities: continuously updated training sets, dynamic validation, real-time feature extraction, and immediate feedback loops that detect and respond to model drift.
Understanding these AI/ML streaming patterns sets the stage for examining how a Machine Learning pipeline works, from data ingestion to deployment and iterative improvement. The next section breaks down this pipeline and highlights the key stages required to train and maintain effective models.
Machine Learning pipeline
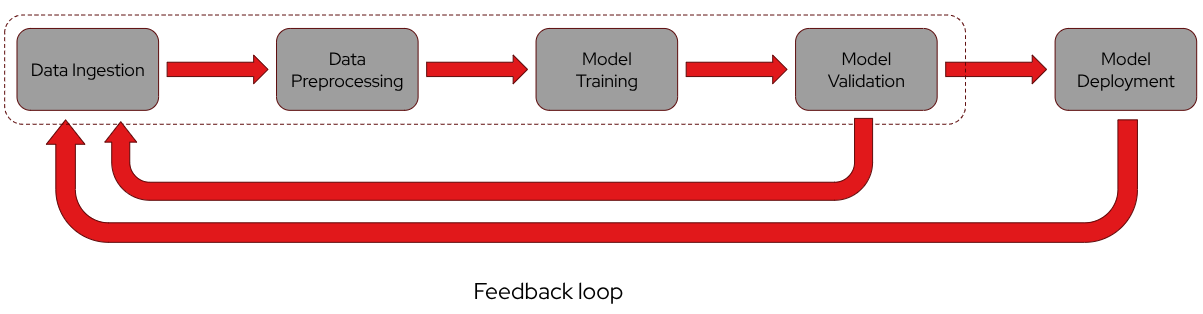
Training a model for deployment and inference involves several key stages:
- data ingestion: data must be sourced and made available for model training from external sources.
- data processing: the raw data is cleaned and preprocessed to enhance its effectiveness during the learning process.
- model training, validation and test: the model is trained using the prepared data and then validated and tested with unseen data from a test set to assess its performance.
- model deployment: the trained model is deployed to serve and make predictions on real-world, unseen data.
Throughout these stages, a feedback loop is crucial. It continuously monitors the model’s performance by collecting metrics and errors on predictions, enabling iterative improvements through re-training.
Batch training in Machine Learning
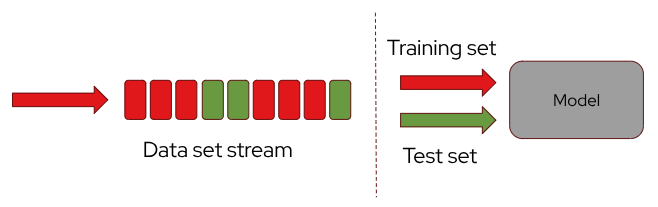
Models are typically trained on batch data. Before training begins, the dataset containing historical data for a specific use case undergoes data cleaning and preparation. This step involves handling missing values, removing duplicates, and normalizing or transforming data to ensure it is in the best possible shape for training. After preparation, the data is split into two sets: the training set and the test set. The training set is used to train the model, allowing it to learn and recognize patterns for making predictions on future unknown data. The test set is used to test the model before serving it for inference.

During the training, the model is often trained over several epochs. An epoch refers to one complete pass through the entire training dataset. Multiple epochs are used to help the model improve its learning and gradually minimize the error in predictions, by fine tuning the model parameters on each epoch.
In addition to the training and test sets, a validation set is often used. The validation set, typically a subset of the training data, is used to evaluate the model’s performance during training and to fine-tune parameters. Common validation metrics include accuracy, precision, recall, and F1 score. These metrics provide insights into how well the model is likely to perform on unseen data.
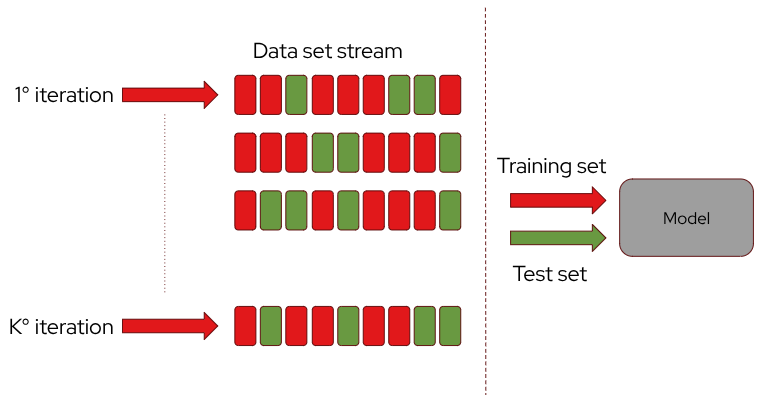
Cross-validation allows the same training set to be reused multiple times by systematically varying the training and validation data. A common approach is k-fold cross-validation, where the dataset is divided into k equally sized folds. The model is then trained k times, each time using a different fold as the validation set while the remaining k-1 folds are used for training.
This process ensures that every data point is used for both training and validation across different iterations. For each configuration, the model is trained over multiple epochs, allowing for fine-tuning of parameters to optimize performance.
Once training is complete, the test set is used to evaluate the model’s final performance by making predictions on this data. The test set helps to ensure that the model generalizes well to new data, which is crucial for its real-world application.
After evaluation, the model is deployed for inference, where it makes predictions on new, unseen data based on what it has learned. Over time, however, the data distributions and patterns can change, leading to what is known as model drift. Model drift occurs when the model’s performance degrades because the data it encounters in the real world has shifted from the data it was trained on. This can result in incorrect or suboptimal predictions.
To maintain accuracy, the model must be monitored for signs of drift and re-trained on updated data as needed, restarting the process from the beginning.
Using Apache Kafka for Real-Time Machine Learning: Training, Testing, and Inference
Data could be stale … So the model, does it need to be re-trained? Yes, continuous training on data streams.
Ingesting data through a data-streaming platform enables a machine learning model to be trained, validated, tested, and to make predictions in real-time. Apache Kafka, as the ingestion system, plays a critical role in this process by efficiently managing data streams.
The pipeline can be structured on several streams:
- training and test streams: two topics can be designated as sources for the training (including validation) and test sets. These streams, referred to as the “training stream” and “test stream,” provide the data needed to build and evaluate the model.
- input unknown data stream: a separate topic is used to ingest unknown data on which the model will make real-time predictions. This input topic is continuously fed with new data points and it’s referred to as the “inference stream”.
- output prediction stream: the final topic stores the model’s predictions. This “prediction stream” holds all the prediction values generated by the model in real time.
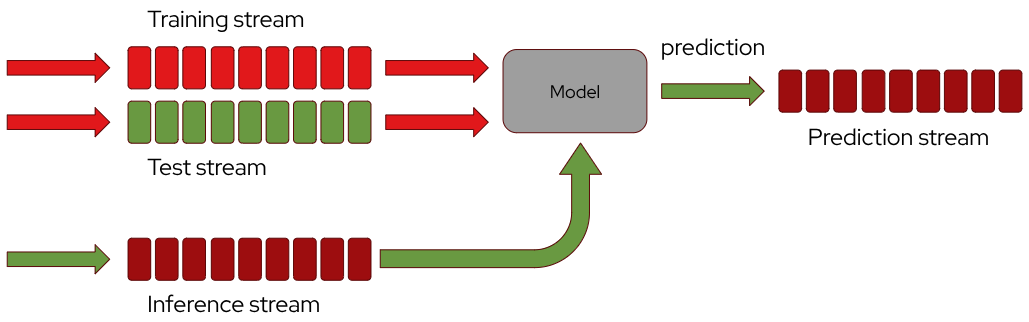
Kafka messages transfer the data across these topics. Besides the message payload, Kafka headers can be utilized to provide additional metadata or contextual information, enhancing the flexibility of the system.
By streaming the training and test sets through Kafka, it’s possible to integrate frameworks like Kafka Streams or Apache Flink to perform real-time preprocessing tasks such as:
- filtering and data cleaning: ensuring that only relevant, high-quality data is used in the model.
- features transformation: selecting and transforming specific features from the data to improve model performance.
- labeling for supervised learning: using Kafka headers in messages to label data in real time, facilitating the supervised learning process.
Instead of using two separate topics for training and testing, you can utilize a single topic and employ a real-time processing framework to filter and split the data into training (with validation) and test sets by using different criteria depending on your needs. A time-based split assigns older events to training and newer ones to testing, preventing leakage and matching real-world behavior. A hash-based random split (using a stable hash of fields like user_id) ensures consistent and unbiased sampling. For models tied to specific entities, an entity-based split keeps all data from the same user or device in the same set. In some cases, business-rule splits, such as differentiation by region or event type, are used when the domain demands targeted evaluation.
For training with k-fold cross validation and fine-tuning parameters across epochs and folds, you can utilize the stream’s rewind feature. By repeatedly filtering and splitting the stream, you can generate various folds for training and validation, as well as obtain distinct test sets.
Because a stream is infinite by definition, there is a need to box the data used to feed the model for training, validation and test. This is where the concept of windowing comes into play.
Windowing the training and test streams involves applying a defined temporal or data-based window to handle the otherwise infinite stream. Even though the stream continuously feeds data in real time, you can impose limits by specifying windows to control the size and scope of the training and test datasets.
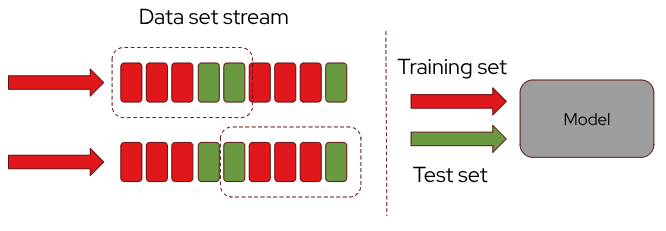
Here’s how you can effectively use windowing:
- temporal windows: define time-based windows (e.g., the last 24 hours) to create manageable chunks of data for training and testing. This ensures that your model is trained and tested on recent and relevant data.
- sliding windows: implement sliding windows that move over the stream, allowing you to continuously update training and test datasets with the latest data while retaining historical context.
- fixed-size windows: set a fixed size for the training and test datasets (e.g., 1,000 records) to process a specific amount of data at a time, regardless of the stream’s ongoing nature.
By applying these windowing techniques, supported by frameworks like Kafka Streams and Apache Flink, you can effectively manage the data flow from an infinite stream, making it feasible to perform training, validation, and testing in real-time while ensuring that the data remains relevant and manageable.
Often, the data ingested through the training and test streams are not enough for the scope. Enriching a data stream involves supplementing the incoming data with additional information from external sources to provide a richer context and enhance the quality of the data used for training a model. Here’s how it can be applied to model training:
- data augmentation: enriching the data stream can involve adding features or metadata that provide more context. This additional context can help the model learn more complex patterns and relationships.
- improving data quality: external data sources can help correct or validate the incoming stream data. This improves the overall quality of the training data.
- adding features: enriching a data stream can involve generating new features from the existing data.
- handling missing values: external sources can help fill in gaps in the incoming data stream.

The enrichment process can involve pulling data from external sources in real time using APIs, database queries or solutions like Kafka Connect to write the additional context information into a topic. Frameworks like Kafka Streams and Apache Flink can integrate this additional information into the data stream as it flows through. This enriched data, now with extra features and improved quality, is then used to train the model. The goal is to enhance the model’s learning by providing more comprehensive training and test sets. Finally, validation can assess how this enrichment impacts the model’s performance.
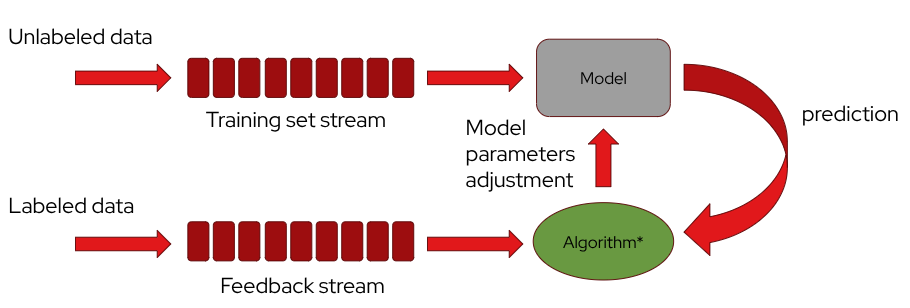
Data streaming can be also used within an online learning system in which a machine-learning model is continuously updated using two Kafka streams. The first stream carries unlabeled data, as a training set stream, that flows directly into the model, producing real-time predictions. When the true outcomes for those predictions become available, they arrive through a second Kafka topic, a feedback stream, as labeled data. An online-learning algorithm, such as a Passive-Aggressive classifier, then compares the model’s earlier predictions with these correct labels and adjusts the model’s parameters on the fly. This creates a continuous feedback loop where the model learns incrementally, adapts to changes in the data, and improves its performance with every new piece of labeled information.
LLMs and Apache Kafka
A foundation model is trained on vast amounts of data collected from across the internet, much of which can quickly become outdated. This reliance on historical data can lead to a lack of current and accurate information. As a result, LLMs may suffer from ‘hallucinations’, generating responses that seem plausible but are actually incorrect. Additionally, foundation models often lack recent data and may struggle with domain-specific knowledge when applied to specialized business contexts.
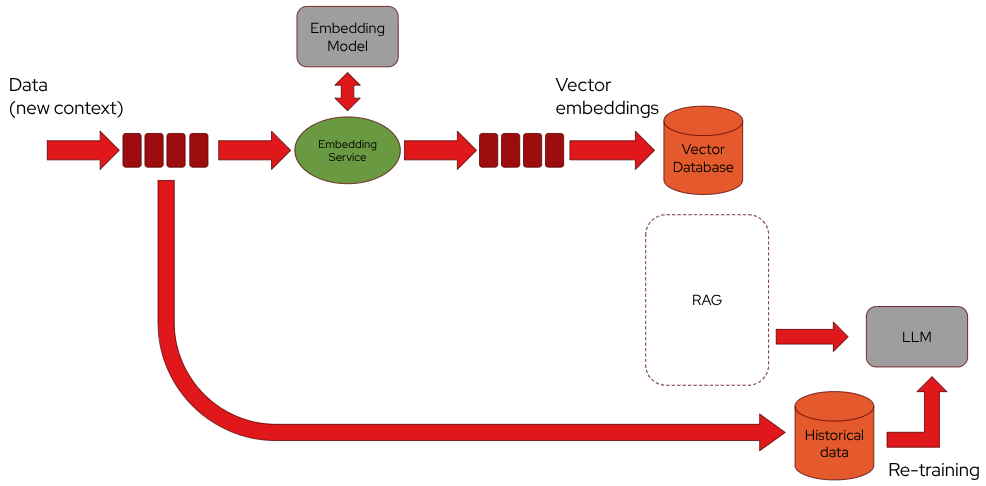
In the RAG (Retrieval Augmented Generation) pattern, a language model is augmented with a retrieval mechanism that pulls relevant data from a vector database to generate more accurate and context-aware responses. This involves generating and storing embeddings (numerical representations) of text data in the vector database. Apache Kafka can play a crucial role in managing the flow of data between different components in this architecture.
Apache Kafka can be used to feed a vector database with embeddings.
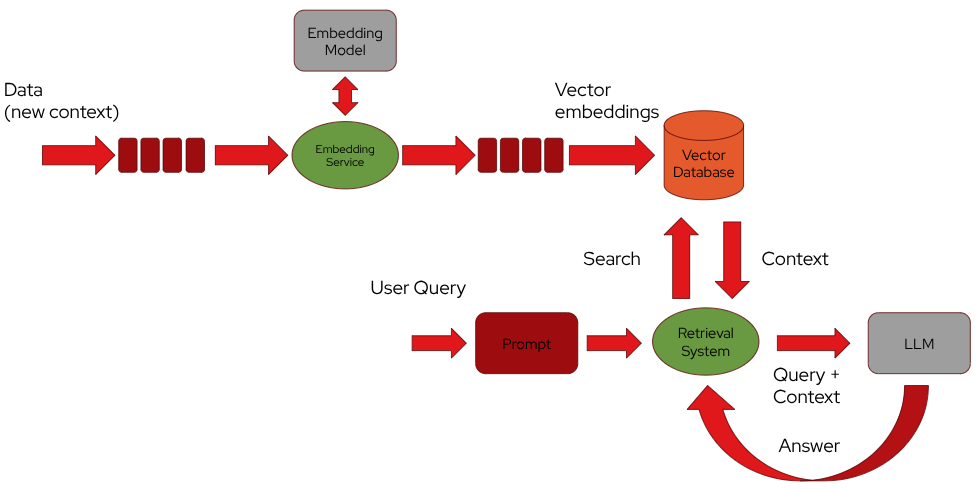
By using a dedicated topic, a producer sends raw data from various sources (i.e. documents, logs, …) and by using frameworks like Kafka Streams and Apache Flink they can be cleaned and tokenized before being converted into embeddings.
Once the data is preprocessed, a dedicated embedding service (which could be another Kafka consumer) reads the preprocessed data from a topic and converts it into embeddings using a pre-trained Embedding model. After generating embeddings, the service can produce the embeddings back into another topic. This topic will act as a queue for embeddings that are ready to be stored in the vector database.
A separate Kafka consumer service is responsible for reading the embeddings from the topic and inserting them into the vector database. This step ensures that the vector database is continuously updated with new embeddings as they are generated.
The key benefits of using Apache Kafka in a RAG architecture are scalability, decoupling components (getting raw data but writing embeddings with two different services), real-time processing (for cleaning and tokenizing) and fault tolerance.
By using Kafka to manage data flow, you ensure that the vector database is continuously and efficiently fed with up-to-date embeddings, supporting robust and dynamic retrieval operations within the RAG pattern.
Within the RAG pattern, Kafka Connect can also be used as one of the components in the architecture for feeding the vector database. It could be used with a source connector to get data from the source and producing the embeddings or with a sink connector to get data from the topic already storing the new data and generating embeddings to the vector database.
The source and sink connectors could be also used together within the same architecture. The source connector pulls raw data from the external source and writes it into a topic. A framework like Kafka Streams and Apache Flink is used to read the raw data from the topic and do some preprocessing and generating embeddings to write into another topic.
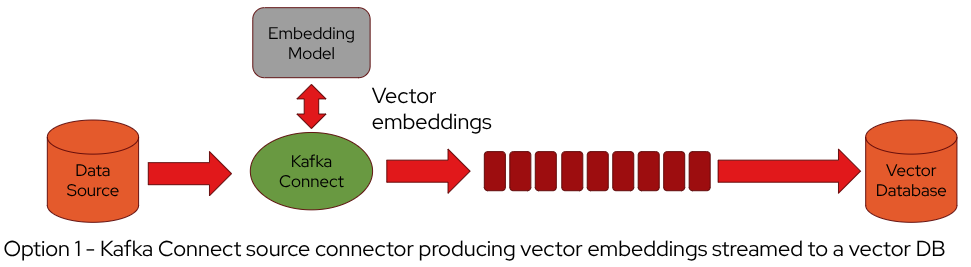
The sink connector reads the embeddings from the topic and writes them into the vector database.
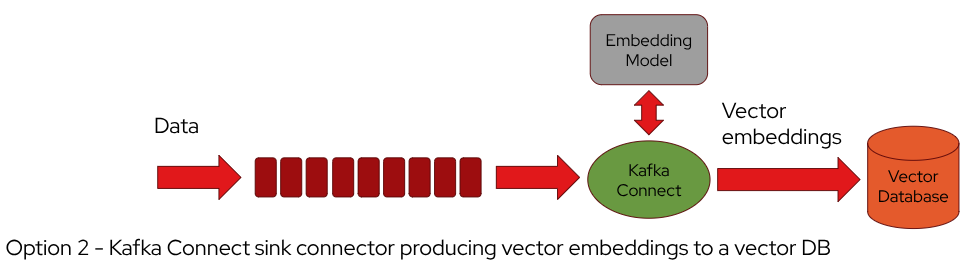
Integrating Kafka Connect into the RAG pattern for generating embeddings enhances automation, simplifies data flow management, and supports scalable, real-time processing. It allows the seamless connection of various data sources and sinks, making the architecture more robust and easier to maintain.
The Kafka topic used for generating the embeddings could be even used as a source of raw data for re-training the LLM. It means that information that is used as additional context through the RAG pattern, at some point could be even used to re-training the foundational model making a specialized version of it. This way the LLM could be used outside of the RAG pattern as well.
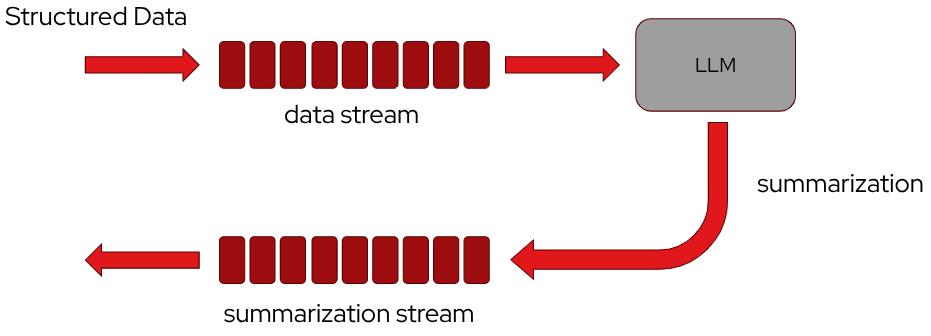
Usually Apache Kafka is used to bring well structured data by also using a Schema registry to store the data schemas. It could be used as feed for an LLM able to make “summarization” on the structured data (i.e. email generations).
The other way around is also applicable, by using an LLM to extract structured data from a text (i.e. customer data from email, chat, …) and put them into a Kafka topic so that they can be processed by microservices.

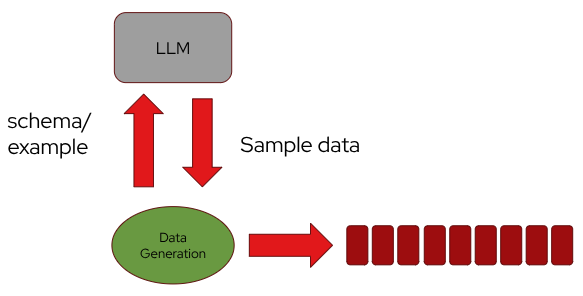
Another way to use an LLM is for data generation. An application can supply a schema or example that defines the desired structure, and the model can produce sample data that adheres to it. This synthetic, structured data can then be fed directly into a stream.
Finally, AI/ML based applications are anyway … applications. As any other software they would need logging or auditing and Apache Kafka is heavily used in that regard.
Bringing the patterns to Kubernetes with Strimzi
When running your Kafka-based AI/ML streaming architecture on Kubernetes, the Strimzi project provides a Kubernetes-native way to operate Kafka and all the supporting components involved in these patterns. Strimzi doesn’t change how the patterns work; instead, it simplifies how you deploy and manage the Kafka ecosystem behind them.
Strimzi exposes Kafka infrastructure through Kubernetes custom resources, allowing the various building blocks used across the patterns to be handled declaratively:
- Streams (topics): By creating
KafkaTopic(s), each stream used in your ML workflows like feature streams, inference results, model updates, data enrichment flows, can be represented and managed as a Kubernetes resource. This makes topic creation, configuration, and lifecycle management part of your standard deployment workflow. - Clients and permissions: Producers, consumers, and ML services can have their credentials and ACLs defined declaratively by using
KafkaUser(s) custom resource. This integrates security and access control directly into your GitOps or CI/CD processes. - Scalability and resilience through Kubernetes: Kafka brokers, the services consuming the streams, and the ML components built around them all benefit from Kubernetes scheduling, scaling, and rolling update capabilities. This aligns well with workloads that need to scale up for training, down for idle inference, or handle fluctuating data rates.
- Kafka Connect as a managed component: Integrations used for training data ingestion, feature extraction pipelines, or pushing predictions to downstream systems can be deployed and controlled via Strimzi-managed Kafka Connect clusters. This keeps the entire data movement layer consistent and cloud-native.
By running Kafka with Strimzi, all the moving pieces involved in your AI/ML streaming patterns like streams, users, connectors, clients, become fully manageable as Kubernetes resources. This provides a unified operational model that reduces complexity and enables teams to focus on building AI/ML logic rather than maintaining infrastructure.
Conclusion
As data-driven architectures evolve, the shift from static datasets to continuous dataflows has reshaped how organizations build, train, and operate modern AI systems. From traditional batch pipelines to real-time model training, online learning, and RAG-powered LLM applications, Apache Kafka has emerged as a unifying backbone, providing the scalable, resilient, and high-velocity streaming foundation required for contemporary AI and ML workloads. Whether enabling continuous feature generation, feeding vector databases, orchestrating enrichment pipelines, or delivering low-latency data for inference, Kafka ensures that machine-learning systems remain accurate, adaptive, and tightly integrated with the ever-changing state of the business.
The next frontier in this evolution is agentic AI. Agents today rely heavily on tools to extend their capabilities through function calling by using MCP (Model Context Protocol), and these tools often act as integration layers that connect the agent to external systems. In real-world scenarios, many of these tools depend on real-time or continuously updated information—exactly the kind of data flow that streaming platforms excel at. A streaming architecture based on Apache Kafka can seamlessly feed fresh data into the tool layer; the tools then return enriched or up-to-date information to the agents, and the agents combine that live operational context with LLM reasoning to fulfill queries or make decisions. This creates a coherent loop where agents orchestrate actions, tools serve as intelligent interfaces to dynamic data, and Kafka ensures that the entire ecosystem operates on timely, trustworthy information.
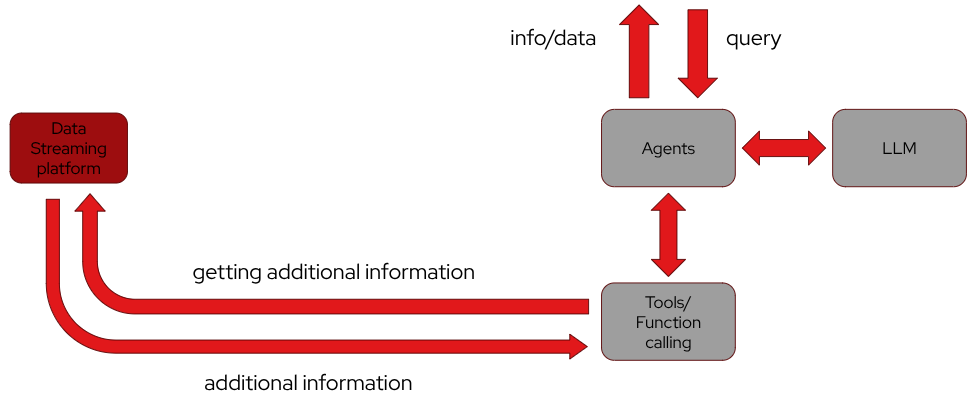
As AI systems continue to move from passive models to active, decision-making agents, Kafka’s role as a streaming backbone will only grow, forming the connective tissue that keeps models grounded, tools informed, and agents capable of acting reliably in real time.